OpenAI 文本嵌入模型之初学者指南
导读
本文将为大家提供关于使用 OpenAI 文本嵌入模型在生成式人工智能应用程序中进行嵌入创建和语义搜索的全面指南。向量嵌入在 AI 中扮演了关键角色,它能够将复杂的非结构化数据转换为机器可处理的向量表示,帮助 AI 模型更高效地理解和处理数据。
什么是向量嵌入与嵌入模型?
向量嵌入
向量嵌入是数据的数字表示,能够捕捉数据中的语义含义与关系,常用于文本、图像、视频、音频等非结构化数据中。通过这些向量,AI 系统可以在高维空间中有效地处理、存储和检索这些数据。类似的单词或数据在向量空间中彼此接近,这便于模型理解它们之间的关系。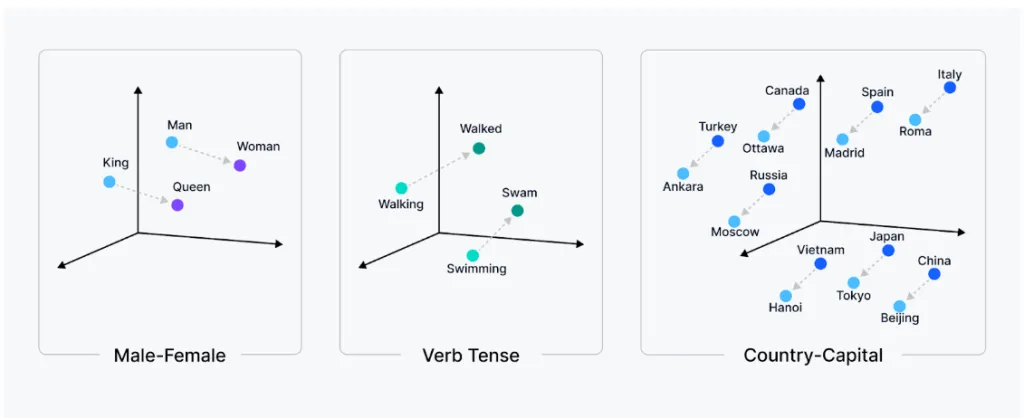
嵌入模型
嵌入模型是一种将非结构化数据转换为向量嵌入的算法。其目的是学习数据中的模式和关系,并在高维空间中表达这些关系。例如,嵌入模型可能会学习到 "king" 和 "queen" 这两个词语在语义上有相似的含义,因此它们在向量空间中应更接近,而像 "banana" 这样的无关词则会远离它们。
向量嵌入的应用场景
向量嵌入广泛应用于语义搜索、聚类、推荐系统、异常检测等任务。在检索增强生成(RAG)系统中,向量嵌入起到桥梁作用,将查询和内容数据映射到高维向量空间中,从而实现更智能的搜索和推荐。
OpenAI 文本嵌入模型
OpenAI 提供了多种嵌入模型,支持语义搜索、聚类、推荐系统等任务。以下是一些常用的 OpenAI 嵌入模型:
- text-embedding-ada-002:性能强劲的第二代嵌入模型,性价比高。
- text-embedding-3-small:性能较优的嵌入模型,适合实时应用。
- text-embedding-3-large:针对复杂任务的高精度模型,资源消耗较大。
模型比较
| 模型 | 描述 | 输出维度 | 最大输入 | 价格 |
|---|---|---|---|---|
| text-embedding-3-large | 高精度模型,适合复杂任务 | 3,072 | 8,191 tokens | $0.13 / 100 万个 tokens |
| text-embedding-3-small | 性能高效,适合实时应用 | 8,191 | 8,191 tokens | $0.10 / 100 万个 tokens |
| text-embedding-ada-002 | 性价比最高的嵌入模型 | 1,536 | 8,191 tokens | $0.02 / 100 万个 tokens |
如何选择模型
选择嵌入模型时需要根据任务需求、性能要求和资源限制进行权衡。例如:
- text-embedding-3-large:适合需要极高精度的任务,但其计算开销较大。
- text-embedding-3-small:适合对实时响应和效率要求较高的应用。
- text-embedding-ada-002:性价比较高的选择,适合大多数常见任务。
使用 OpenAI 生成向量嵌入
下面我们来看看如何使用 OpenAI 的嵌入模型生成向量嵌入,并将其存储在 Zilliz Cloud 中进行语义搜索。
1. 配置与工具
我们将使用 PyMilvus,这是 Milvus 的 Python SDK,可以与 OpenAI 嵌入模型无缝集成。
2. 生成向量嵌入并存储
使用 text-embedding-ada-002 模型:
from pymilvus.model.dense import OpenAIEmbeddingFunction
from pymilvus import MilvusClient
OPENAI_API_KEY = "your-openai-api-key"
ef = OpenAIEmbeddingFunction("text-embedding-ada-002", api_key=OPENAI_API_KEY)
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England."
]
# Generate embeddings for documents
docs_embeddings = ef(docs)
queries = ["When was artificial intelligence founded",
"Where was Alan Turing born?"]
# Generate embeddings for queries
query_embeddings = ef(queries)
# Connect to Zilliz Cloud with Public Endpoint and API Key
client = MilvusClient(
uri="ZILLIZ_PUBLIC_ENDPOINT",
token="ZILLIZ_API_KEY"
)
COLLECTION = "documents"
if client.has_collection(collection_name=COLLECTION):
client.drop_collection(collection_name=COLLECTION)
client.create_collection(
collection_name=COLLECTION,
dimension=ef.dim,
auto_id=True
)
for doc, embedding in zip(docs, docs_embeddings):
client.insert(COLLECTION, {"text": doc, "vector": embedding})
results = client.search(
collection_name=COLLECTION,
data=query_embeddings,
consistency_level="Strong",
output_fields=["text"]
)
使用 text-embedding-3-small 模型:
from pymilvus import model, MilvusClient
OPENAI_API_KEY = "your-openai-api-key"
ef = model.dense.OpenAIEmbeddingFunction(
model_name="text-embedding-3-small",
api_key=OPENAI_API_KEY,
)
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England."
]
# Generate embeddings for documents
docs_embeddings = ef.encode_documents(docs)
# Generate embeddings for queries
queries = ["When was artificial intelligence founded",
"Where was Alan Turing born?"]
query_embeddings = ef.encode_queries(queries)
# Connect to Zilliz Cloud
client = MilvusClient(
uri="ZILLIZ_PUBLIC_ENDPOINT",
token="ZILLIZ_API_KEY"
)
COLLECTION = "documents"
if client.has_collection(collection_name=COLLECTION):
client.drop_collection(collection_name=COLLECTION)
client.create_collection(
collection_name=COLLECTION,
dimension=ef.dim,
auto_id=True
)
for doc, embedding in zip(docs, docs_embeddings):
client.insert(COLLECTION, {"text": doc, "vector": embedding})
results = client.search(
collection_name=COLLECTION,
data=query_embeddings,
consistency_level="Strong",
output_fields=["text"]
)
结语
OpenAI 文本嵌入模型为开发者提供了强大的向量嵌入工具,适用于广泛的 AI 应用场景,如语义搜索、内容推荐和异常检测。结合向量数据库(如 Milvus 和 Zilliz Cloud),可以实现高效的向量存储和搜索,构建更智能的 AI 系统。
希望这篇指南能帮助你快速上手 OpenAI 嵌入模型,探索更多生成式 AI 应用的可能性。