为什么要放弃UUID作为MySQL主键?
引言
在数据库设计中,自增主键最为常见,但当面对数据删除等场景时,自增主键容易被猜测,从而存在安全隐患。因此,UUID(Universally Unique Identifier)被广泛采用,因其全球唯一性和不可预测性,成为不少开发者的选择。我最初的项目也是使用UUID作为MySQL主键,然而随着业务发展,我们逐渐替换成了雪花算法生成的ID。本文将深入探讨UUID和雪花算法的差异,并解释为什么在实际项目中,我们选择了雪花算法。
什么是UUID?
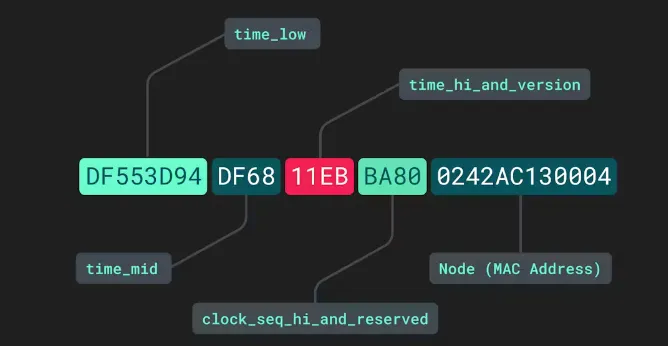
UUID是一种全球唯一的标识符,通常用于生成在分布式系统中不重复的标识。它具有以下特点:
- 全局唯一性:理论上保证每个UUID都是唯一的。
- 不可预测性:生成方式随机,难以预测。
- 标准化:遵循RFC 4122标准。
- 自包含:无需依赖外部系统,独立生成。
UUID由32个十六进制字符组成,常见格式为8-4-4-4-12,如:550e8400-e29b-41d4-a716-446655440000。常用的UUID版本包括:
- Version 1:基于时间戳和MAC地址,可能会引发隐私问题。
- Version 4:完全随机生成,重复的概率极低。
- Version 3 & 5:基于命名空间的哈希算法生成,分别使用MD5和SHA-1。
生成UUID示例
在Java中,生成UUID的代码如下:
import java.util.UUID;
public class Main {
public static void main(String[] args) {
UUID uuid = UUID.randomUUID();
System.out.println("Generated UUID: " + uuid);
}
}
虽然UUID提供了全球唯一性,但随着业务发展和需求变化,我接触到了雪花算法,并改变了原有的观点。
什么是雪花算法?
雪花算法(Snowflake Algorithm)由Twitter开发,用于分布式系统中生成全局唯一且递增的长整型ID。其主要特点包括:
- 全局唯一性:即使在网络分区的情况下,也能保证生成的ID不会重复。
- 高效性:基于时间戳和机器标识生成,毫秒级响应,适合高并发环境。
- 有序性:ID是递增的,有利于数据库的插入和查询优化。
- 占用空间小:生成的ID为64位整数,仅占用8字节,比UUID小。
- 易于扩展:支持分布式系统下的多节点扩展。
雪花算法生成器示例
以下是雪花算法的实现:
public class SnowflakeIDGenerator {
private static final long EPOCH = 1722947753723L;
private final long workerId;
private final long datacenterId;
private final long sequence;
private final AtomicLong lastTimestamp = new AtomicLong(EPOCH - 1L);
public SnowflakeIDGenerator(long workerId, long datacenterId) {
// 检查workerId和datacenterId的有效性
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = 0L;
}
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp.get()) {
throw new RuntimeException("Clock moved backwards.");
}
if (lastTimestamp.get() == timestamp) {
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp.get());
}
} else {
sequence = 0L;
}
lastTimestamp.set(timestamp);
return ((timestamp - EPOCH) << TIMESTAMP_LEFT_SHIFT) |
(datacenterId << DATACENTER_ID_SHIFT) |
(workerId << WORKER_ID_SHIFT) |
sequence;
}
protected long timeGen() {
return System.currentTimeMillis();
}
}
使用示例
public static void main(String[] args) {
SnowflakeIDGenerator generator = new SnowflakeIDGenerator(1, 1);
for (int i = 0; i < 10; i++) {
System.out.println(generator.nextId());
}
}
为什么选择雪花算法而不是UUID?
在MySQL中,使用雪花算法作为主键有多个好处,尤其在性能和存储效率上优于UUID。
1. 存储空间
- UUID:UUID为128位(16字节),占用较多空间。
- 雪花算法:生成的ID为64位(8字节),节省了一半的存储空间,尤其在大规模数据表中,存储效率更高。
2. 性能
- UUID:UUID v4基于随机数生成,虽然速度快,但不如雪花算法稳定。而UUID v1/v2基于MAC地址和时间戳,可能会引发隐私问题。
- 雪花算法:基于时间戳和简单的数学运算生成,速度极快,毫秒级响应,适合高并发场景。
3. 排序性能
雪花算法生成的ID是递增的,这有助于数据库索引的优化。MySQL使用B+树结构存储索引,当主键递增时,可以减少页面分裂,提高插入和查询性能。而UUID生成的ID是随机的,容易导致索引不连续,降低性能。
4. 并发性能
雪花算法非常适合高并发环境,它能够在多台服务器上生成唯一的ID,避免冲突。而UUID虽然也可以用于并发场景,但其生成机制效率不如雪花算法。
5. 数据库性能
MySQL在处理连续的整数主键时性能更好,雪花算法生成的递增ID利用了InnoDB的B+树结构,能够加快数据插入和检索操作。而UUID的随机性会导致索引分裂,影响插入和查询性能。
6. 可预测性和易理解性
雪花算法生成的ID可以根据时间戳解析出生成时间,便于调试和审计。UUID的随机性虽然确保了唯一性,但难以解读和调试。
总结
选择雪花算法作为MySQL主键的原因主要是出于性能、存储空间和数据库操作效率的考虑。尽管UUID是一种广泛使用的唯一标识符,但在高并发、分布式系统中,雪花算法凭借其全局唯一性、递增性和高效性,成为了主键生成的最佳选择。