VibeVoice 深度解析:微软如何用 7.5Hz 超低帧率暴力破解 90 分钟长语音合成——开源语音 AI 的技术革命
2026-05-10 23:20:20 +0800 CST view 517
FishSpeech是一个全新的文本到语音(TTS)解决方案,采用变分自编码器、声码器和生成对抗网络等先进技术,提供高质量、自然的语音合成
2024-11-19 04:18:33 +0800 CST view 2424
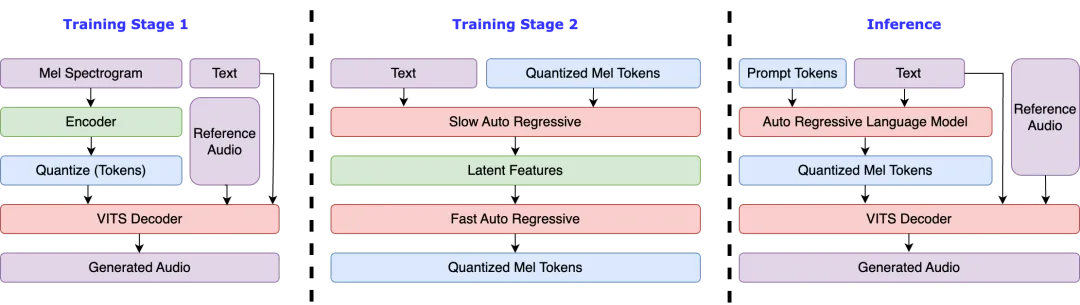
万字深度解析 Microsoft VibeVoice:当开源遇上前沿语音AI——从 TTS 到 ASR 的全栈语音合成与识别技术革命(2026)
2026-07-01 04:12:36 +0800 CST view 73
VibeVoice 深度拆解:微软如何用 LLM+扩散模型重新发明语音合成——从双Tokenizer到90分钟超长对话的全链路技术实战
2026-05-02 22:34:34 +0800 CST view 385
VibeVoice 深度解析:微软开源语音AI的架构革命,7.5Hz帧率如何重塑长音频处理范式
2026-04-22 01:51:38 +0800 CST view 439
Python中使用macosx-tts库来实现MacOS的文本到语音功能
2024-11-18 23:46:50 +0800 CST view 1667
VibeVoice 深度解析:微软如何用双分词器与扩散解码器重新定义语音AI的天花板
2026-04-14 11:25:32 +0800 CST view 588
VibeVoice 深度实战:当微软把「情感语音合成」塞进 1.5B 参数模型——从 90 分钟长音频到多说话人混搭的生产级完全指南(2026)
2026-06-13 23:15:58 +0800 CST view 235
VibeVoice 深度解析:微软如何用连续语音Tokenizer和Next-Token Diffusion重塑语音AI边界
2026-04-15 22:19:22 +0800 CST view 563
微软 VibeVoice 深度解析:突破长音频处理的语音AI架构革命
2026-05-19 05:47:47 +0800 CST view 405
OmniVoice Studio:5k Star开源声音克隆工具,646种语言,无GPU也能跑
2026-05-28 20:50:27 +0800 CST view 408
Vosk-API 是一款开源的离线语音识别工具包
2024-11-19 07:51:49 +0800 CST view 3822
VibeVoice 深度实战:当微软把「90分钟长语音」塞进开源——从 Next-Token Diffusion 架构到生产级 TTS/ASR 全栈引擎的完全指南(2026)
2026-06-14 17:16:29 +0800 CST view 225
零成本在本地跑 Whisper:从视频自动生成双语字幕
2026-06-08 15:48:58 +0800 CST view 314
MOSS-TTS-Nano:0.1B 参数的开源语音模型,CPU 直跑,浏览器里都能用
2026-04-25 08:17:20 +0800 CST view 1050
Pynini是一个开源的Python库,专注于构建语言模型和处理字符串
2024-11-19 04:26:54 +0800 CST view 3638
VibeVoice深度实战:微软如何用扩散模型重塑语音合成的技术边界
2026-05-19 19:14:43 +0800 CST view 335
Papacito OS:本地转录+图片OCR+搜索,开源AI第二大脑有点实用
2026-06-20 13:43:05 +0800 CST view 167
VibeVoice 深度解析:微软如何用 7.5Hz 超低帧率重塑语音 AI——从 ASR 到实时 TTS 的全栈技术内幕
2026-04-17 10:48:42 +0800 CST view 618
微软开源 VibeVoice:60分钟长音频转录、实时TTS,这个语音AI全家桶有点猛
2026-04-08 11:36:14 +0800 CST view 663
OmniVoice 深度实战:当小米 k2-fsa 团队用扩散语言模型重塑语音合成——从零样本克隆到 600 语言高保真 TTS 的生产级完全指南(2026)
2026-06-15 14:21:23 +0800 CST view 352