Dify:92K Star开源LLM应用平台,零代码构建生产级AI工作流,Docker一键部署
2026-04-16 19:09:32 +0800 CST view 521
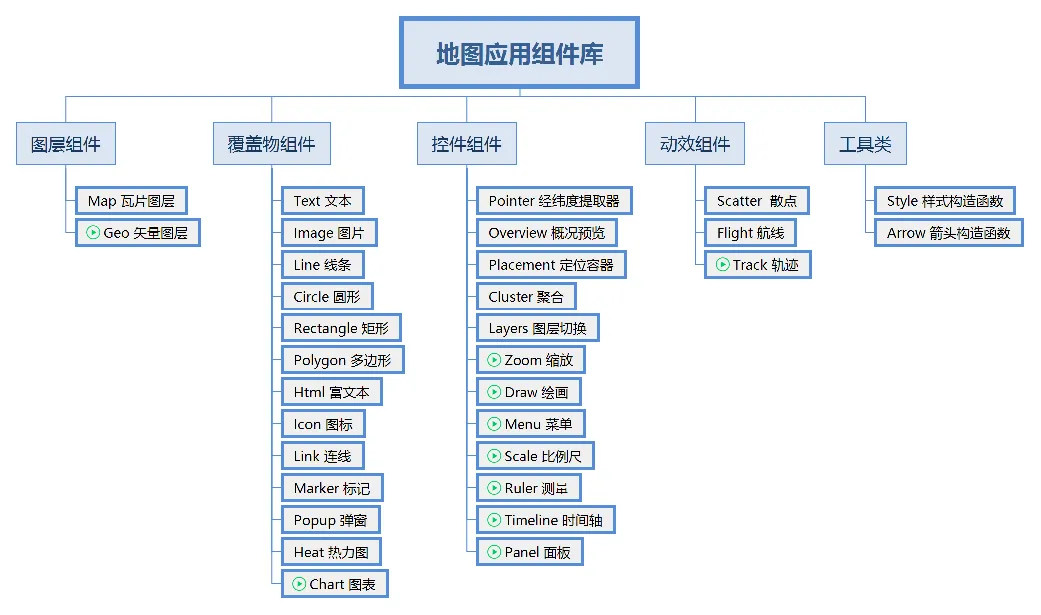
xdh-map是一款基于OpenLayers的Vue地图应用组件库,旨在简化地图集成过程,适合前端开发者使用
2024-11-19 09:44:23 +0800 CST view 2693
达梦图数据库 V4.0 深度实战:图原生+向量深度融合,千亿级数据让AI真正"懂业务"
2026-05-16 13:15:18 +0800 CST view 245
达梦GDMBASE V4.0揭秘:千亿级图数据库与向量数据库的"原生融合"架构革命
2026-05-16 13:15:41 +0800 CST view 280
Redis 8.0 深度解析:30项性能飞跃、8种新数据结构与重回开源的破局之路
2026-05-12 18:40:32 +0800 CST view 219
在MySQL中全局回滚一张表数据的多种方法,包括使用事务、备份与恢复、触发器和二进制日志
2024-11-18 13:59:43 +0800 CST view 1542
10亿级数据高效写入MySQL:架构设计与实战优化
2025-03-29 15:24:44 +0800 CST view 1363
sql语句分别按日,按周,按月,按季统计金额
2024-11-17 05:05:22 +0800 CST view 3131
DuckLake v1.0 深度解析:用关系型数据库如何颠覆湖仓一体的"小文件地狱"
2026-04-19 03:14:23 +0800 CST view 540
批量导入scv数据库
2024-11-17 05:07:51 +0800 CST view 3106
使用 Go 语言并发处理 CSV 文件到数据库
2024-11-18 12:08:55 +0800 CST view 1716
SpacetimeDB 深度实战:当数据库成为服务器——从"光速开发"到生产级实时应用的完全指南(2026)
2026-06-11 02:45:57 +0800 CST view 69
mysql int bigint 自增索引范围
2024-11-18 07:29:12 +0800 CST view 3220
RedFox:一个 API Key 打通全网自媒体数据,45 个开源 Agent Skill 免费部署
2026-06-11 10:35:17 +0800 CST view 511
PostgreSQL 18 深度实战:从 I/O 子系统重构到 AI 原生向量数据库——新一代开源关系型数据库的架构完全指南
2026-05-23 15:16:30 +0800 CST view 214
MySQL用命令行复制表的方法
2024-11-17 05:03:46 +0800 CST view 3166
mysql删除重复数据
2024-11-19 03:19:52 +0800 CST view 3264

千万级数据的全表更新的正确方式
2024-11-19 01:43:51 +0800 CST view 1804
shore-kafka是一个为Python开发者设计适用于大数据流处理
2024-11-19 02:00:32 +0800 CST view 1670
ascacou是一个Python库,专注于数据分析和处理
2024-11-18 06:19:36 +0800 CST view 1450
达梦数据库 DM9 深度解析:国产数据库的「集中分布一体化」革命——从 450 项新特性到 AI 原生架构的全链路技术拆解
2026-05-02 17:07:56 +0800 CST view 317
Python中的`real-estate`库,旨在帮助房地产行业的数据分析人员获取和处理房地产数据
2024-11-18 19:33:13 +0800 CST view 1497
Nushell 0.111 深度解析:用 Rust 重写 Shell,让命令行终于有了数据类型
2026-05-12 01:44:53 +0800 CST view 311
DuckDB 深度实战:当嵌入式OLAP遇见现代数据分析——从列式存储到生产级分析管道的完全指南(2026)
2026-06-13 01:46:26 +0800 CST view 36