Fiber v3 深度拆解:当 Go Web 框架把 Ctx 变成接口——从 fasthttp 底座、接口化上下文到 Host 鉴权与正则路由的工程全貌(2026)
2026-07-19 03:42:46 +0800 CST view 116
DeerFlow 2.0 深度解析:57K Star 背后的超级智能体编排革命
2026-04-21 04:15:29 +0800 CST view 648
微信小程序开发资源汇总
2026-05-11 16:11:29 +0800 CST view 541
FastAPI是一个现代化、高性能的PythonWeb框架,易于学习和使用。它支持快速编码、请求验证和自动文档生成
2024-11-18 23:34:20 +0800 CST view 1892
基于Webman + Vue3中后台框架SaiAdmin
2024-11-19 09:47:53 +0800 CST view 2374
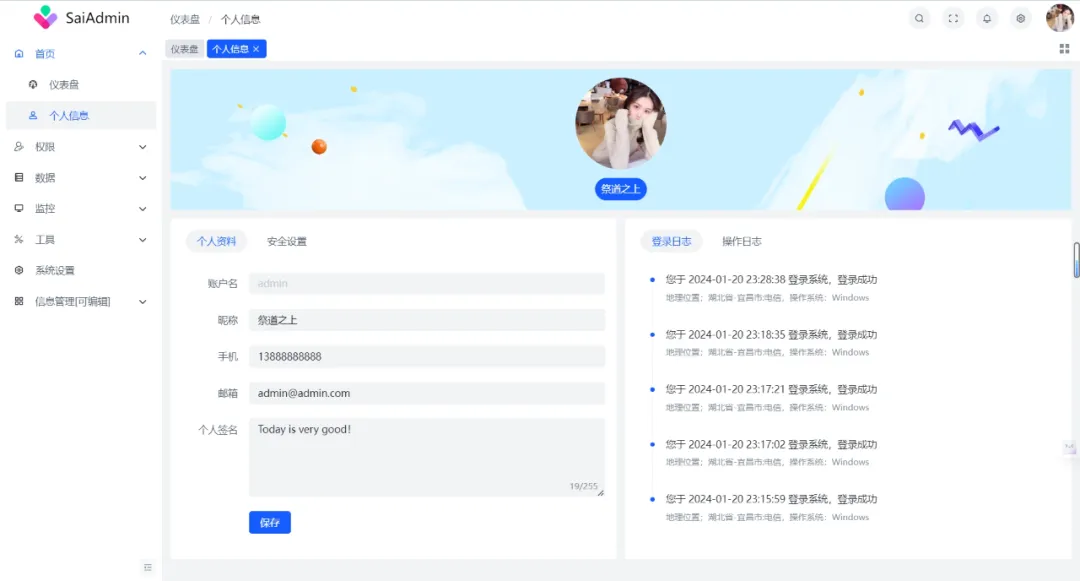
开源 | 一款基于 Vue 的低代码,6K star 的可视化表单设计器工具,轻松搞定表单,支持多端适配
2024-11-19 08:33:51 +0800 CST view 3422
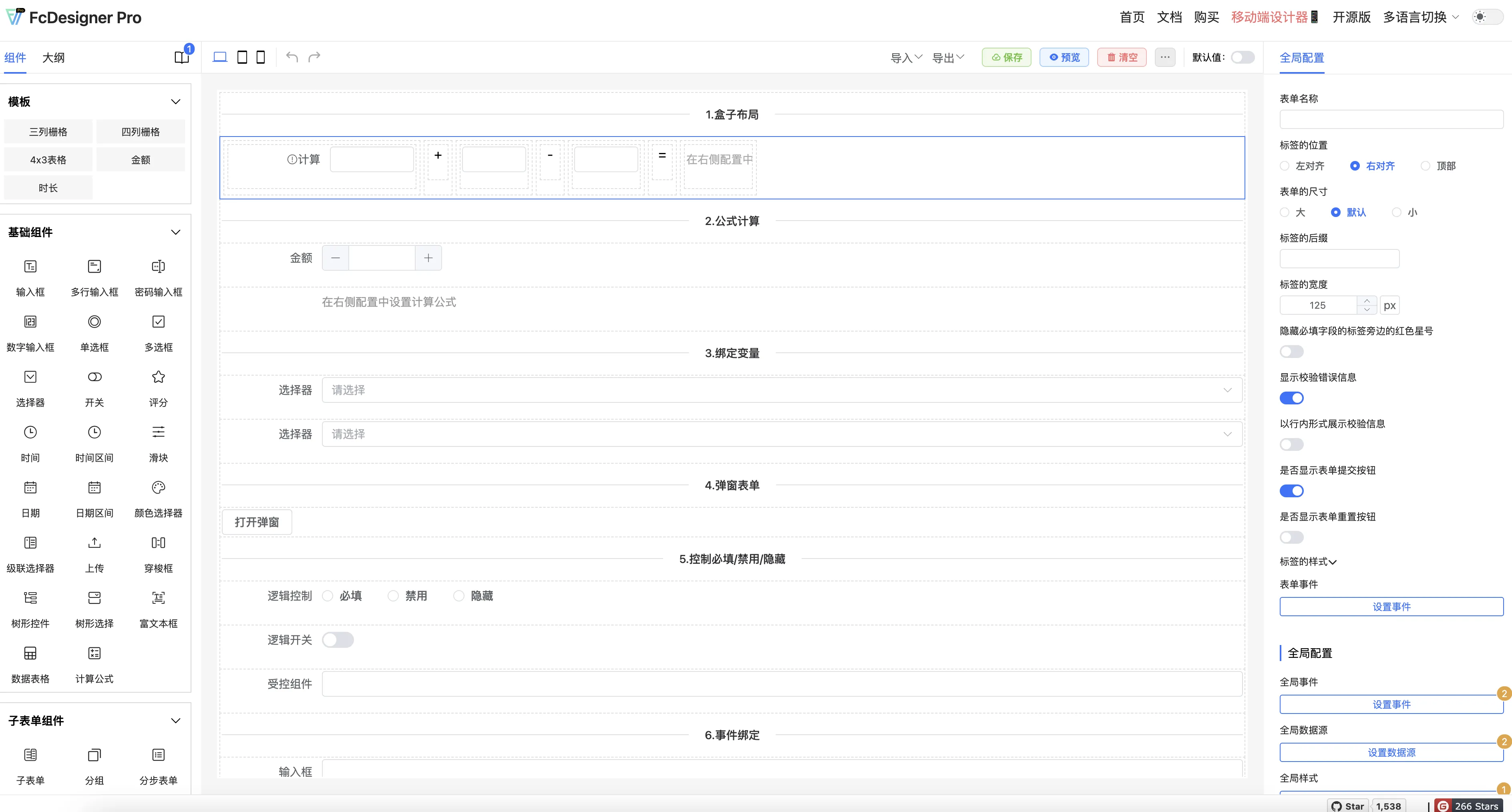
Svelte 5 深度实战:从编译时优化到 Runes 响应式系统——2026 年前端框架性能之巅完全指南
2026-05-24 03:30:59 +0800 CST view 533
Svelte 5 编译时优化完全指南:用 Runes 响应式系统碾压虚拟 DOM
2026-05-24 03:31:37 +0800 CST view 564
PHP高性能框架Workerman的核心技术epoll,分析了其如何利用IO多路复用机制实现高性能
2024-11-19 03:09:27 +0800 CST view 1865
DeerFlow 2.0深度解析:字节跳动开源的超级智能体框架——从LangGraph重构到生产级AI Agent工程化实践
2026-05-17 12:15:20 +0800 CST view 622
React 19 useActionState 深度解析:从三Hook协作到循环队列调度的内核级剖析
2026-05-17 12:44:17 +0800 CST view 532
使用 Vue3、Shadcn UI、Vite、TypeScript 和 Monorepo 构建的现代 vue 管理面板。 等多种 UI 的中后台系统框架
2024-11-18 18:53:38 +0800 CST view 3191
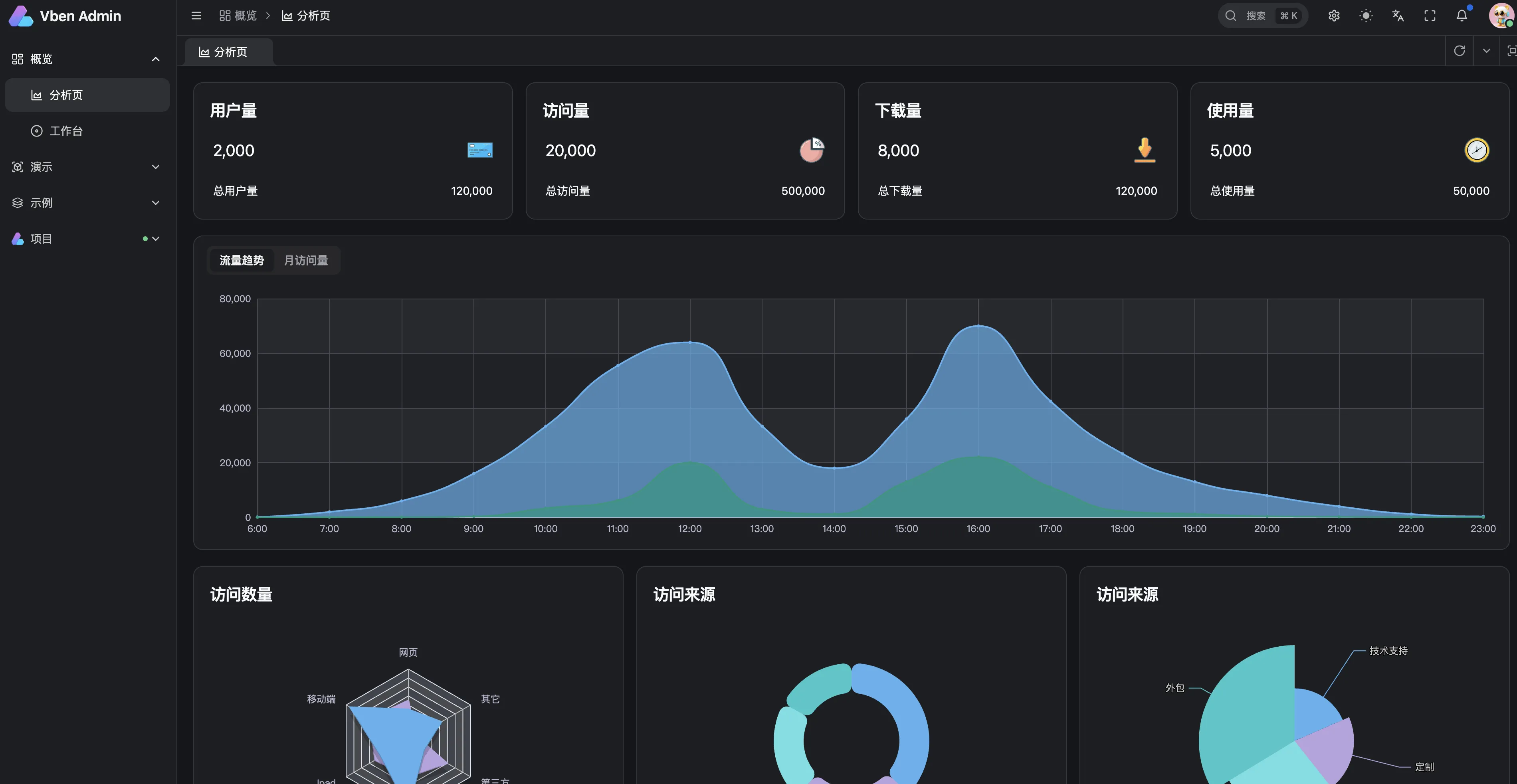
Vue 3 新指令 v-memo:终极渲染性能优化神器**
2025-08-06 12:58:41 +0800 CST view 1128
vue打包后如何进行调试错误
2024-11-17 18:20:37 +0800 CST view 3785
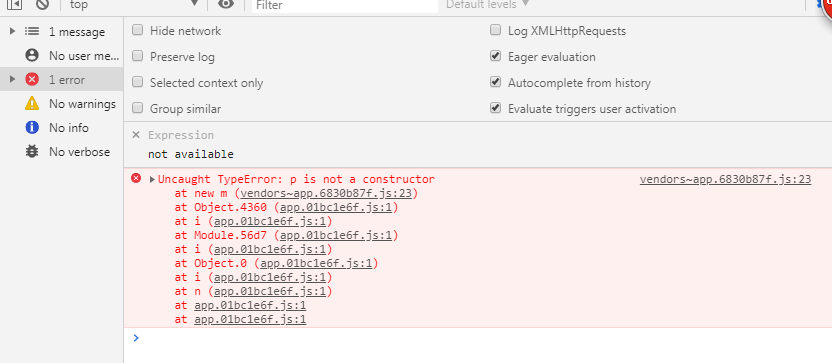
Superpowers 深度解析:如何用「工程纪律」管住 AI 编程的混沌——从 TDD 到自我审查的七门必修课
2026-04-12 14:56:47 +0800 CST view 733
Hermes Agent 深度拆解:当AI Agent学会「记住」——从三层记忆架构、自进化闭环到多平台网关的工程全貌(2026)
2026-07-19 10:44:18 +0800 CST view 163
使用 Vue3 和 Axios 实现 CRUD 操作
2024-11-19 01:57:50 +0800 CST view 1768
Vue.js 的响应式数据是如何实现的?
2024-11-18 09:32:05 +0800 CST view 1358
两年磨一剑:Encore如何用6.7万行Rust重写TypeScript运行时,性能提升10倍的深度技术解析
2026-05-11 22:17:14 +0800 CST view 510
如何使用Vue3的组合式API创建一个动态计时器组件
2024-11-19 01:45:23 +0800 CST view 1648
Gin 1.12 深度解析:从 TextUnmarshaler 到 HTTP/3,Go Web 框架的又一次进化
2026-04-21 09:51:28 +0800 CST view 667
ClawKeeper 深度解析:当「用智能体监管智能体」从概念走向工程——三层防御架构如何为 OpenClaw 系上数字安全带
2026-04-12 20:56:05 +0800 CST view 779
前端框架Signal响应式革命:当细粒度更新击碎虚拟DOM神话——从Svelte 5 Runes到Angular Signals的深度实战指南
2026-06-23 12:57:55 +0800 CST view 259